As a beginning computer user in my past, I had a pattern that I'm sure you're all too familiar with. Your files get all cluttered up, so you decide to organize them. You put all your music in one folder, all your documents in another etc. Finally, all your files are nice and neat but it never stays that way. It eventually clutters up again. Some users opt to use a search function, so they wont have to care for organization. Others may choose to use a special file organization program. I, however, have chosen a system that's a little bit unconventional.
Pick a place that's easy to access as the root directory of where you're going to put all your files. Next, create two directories, Cabinet and Library. Cabinet is where you're going to place all your files that you continuously modify and aren't really set in stone. Your financial documents, current projects, grocery lists, etc. The Library, on the other hand, stores data that wont change very often or at all. Be it your music collection, books, recipes, ROM dumps, video games etc.
The Cabinet can be sorted however you like. It's meant to change frequently anyways, and you'll likely settle upon a system that you'll stick with for a long time eventually. If you have any ideas on how the Cabinet could be sorted in such a way that it wouldn't need to be changed for a long time, let me know! As for the Library on the other hand, the top level directory within it is always the function of the content within them.
In this example, the things I want to store are a book within the public domain called "Flora Symbolica" - you'll never know when you'll need it and two music albums, one called Show Yourself Spirit Fox by ABSRDST and Behold... The Sirens! by Nagra.
In this case, we create two top level directories, Music and Documents. You can also call it Books, but this is the convention I've chosen. Within each, for everything we want to store, we use a medium/artist or publisher/album/content directory chain. In both cases, the medium directory isn't applicable, but if you're storing say, a classic video game collection, you'd use the medium directory to sort which console the game belongs to.
Our directory listing should look like:
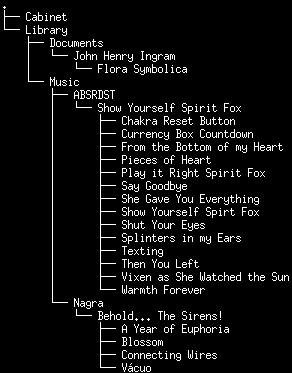
This is great and all, and it does scale wonderfully in the real world, but as someone who's been called OCD on Reddit for asking too many questions regarding the nine essential amino acids necessary in the human diet, this obviously will not do.
Notice that the files aren't in the order on the album, but in alphabetical order. What if the files silently get corrupted, how could we know? Who are these artists and what are these books and albums about? What about album covers and song lyrics?
This is where the beauty of supplementary data comes into play. Every directory where it makes sense should be populated with a Metadata file. For the book, I have one for the book itself and one for the author. As for the music files, I have one for each song, album and artist as well as a cover.png file and a playlist.m3u file. If any of the songs within those albums had lyrics that could be understood, I'd also have a special file containing the lyrics of each song, usually .srt or .lrc format. These lyrics formats, like our directory tree structure, are very easy for both a human and a computer to read. This'll become a visible trend while I describe the functions of each file. Note that I'm using cover.png files as opposed to cover.jpg's. This is because png is a lossless format, so all data remains intact throughout conversions. This is an important property. The music files in this example are mp3's, but I prefer to use FLAC due to its lossless properties, but the files inflate quite a bit, so using the original file format in the meantime isn't a bad thing so long as mp3 is an open format, which it is but at one point wasn't. Jpegs and mp3's are lossy formats, which means that every time you export a file as these formats, some data is destroyed and the quality lost as a trade off for a smaller file size. In a library where we want data to ideally last forever at the highest quality possible, this will not do. The playlist.m3u file is very easily human and computer read. It's plaintext and contains all the file paths to the songs within an album in the correct playing order.
The metadata files on the other hand, contain all sorts of information regarding what ever it is they represent. From the discography of each musician to the day that a particular author passed away as well as links to their respective Wikipedia pages. Did you know, for example, that the author of Flora Symbolica's family knew Edgar Allan Poe personally? I keep this information stored within the very easily human and machine readable .ini format. I'll give you some examples, after I quickly mention that I also hold checksums to various related files within these metadata files in order to ensure that if they get accidentally corrupted, because data doesn't last forever, I could detect this easily and restore the data from backups.
Now, as for an easy way to search through the library, running 'grep -ir "" .' within the top level directory will search recursively all files within and below the current working directory for any file that matches the pattern within quotes. Notice how this file management technique uses only the tools already likely provided on your system? This is to ensure that the methods used will likely still be usable in the future and if not, the system can be easily changed. This system can also scale very well and continue to work well regardless of how large the library becomes.
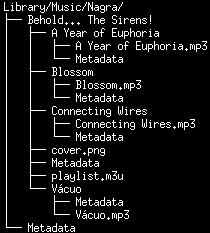 Full Directory listing
Full Directory listing
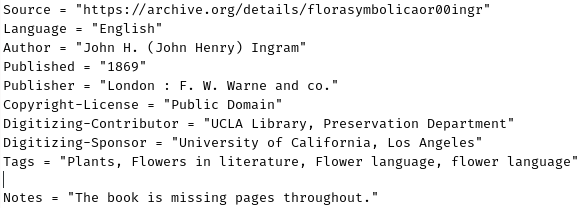 Metadata file for Flora Symbolica
Metadata file for Flora Symbolica
 Playlist file for Show Yourself Spirit Fox
Playlist file for Show Yourself Spirit Fox

Comments
No comments yet. Be the first to react!